Database vendors typically release patches with bug/security fixes on a monthly basis, why should we care? The news is full of reports of security breaches and hacked systems, so unless security is not a concern, you might want to have the most current security fixes on your systems. Major versions are rarer, and usually harder (and riskier) to upgrade to. But they might bring along some important features that make the upgrade worth the effort.
In this blog post, we will cover one of the most basic tasks of the DBA - minor and major database upgrades.
This is the sixth installment in the ‘Become a MySQL DBA’ blog series. Our previous posts in the DBA series include Replication Topology Changes, Schema Changes, High Availability, Backup & Restore, Monitoring & Trending.
MySQL upgrades

Once every couple of years, a MySQL version becomes outdated and is not longer supported by Oracle. It happened to MySQL 5.1 on December 4, 2013, and earlier to MySQL 5.0 on January 9, 2012. It will also happen to MySQL 5.5 somewhere in 2018, 8 years after the GA was released. It means that for both MySQL 5.0 and MySQL 5.1, users cannot rely on fixes - not even for serious, security bugs. This is usually the point where you really need to plan an upgrade of MySQL to a newer version.
You won’t be dealing only with major version upgrades, though - it’s more likely that you’ll be upgrading to minor versions more often, like 5.6.x -> 5.6.y. Most likely, it is so that the newest version brings some fixes for bugs that affect your workload, but it can be any other reason.
There is a significant difference in the way you perform a major and a minor version upgrade.
Preparations
Before you can even think about performing an upgrade, you need to decide what kind of testing you need to do. Ideally, you have a staging/development environment where you do tests for your regular releases. If that is the case, the best way of doing pre-upgrade tests will be to build a database layer of your staging environment using the new MySQL version. Once that is done, you can proceed with a regular set of tests. More is better - you want to focus not only on the “feature X works/does not work” aspect but also performance.
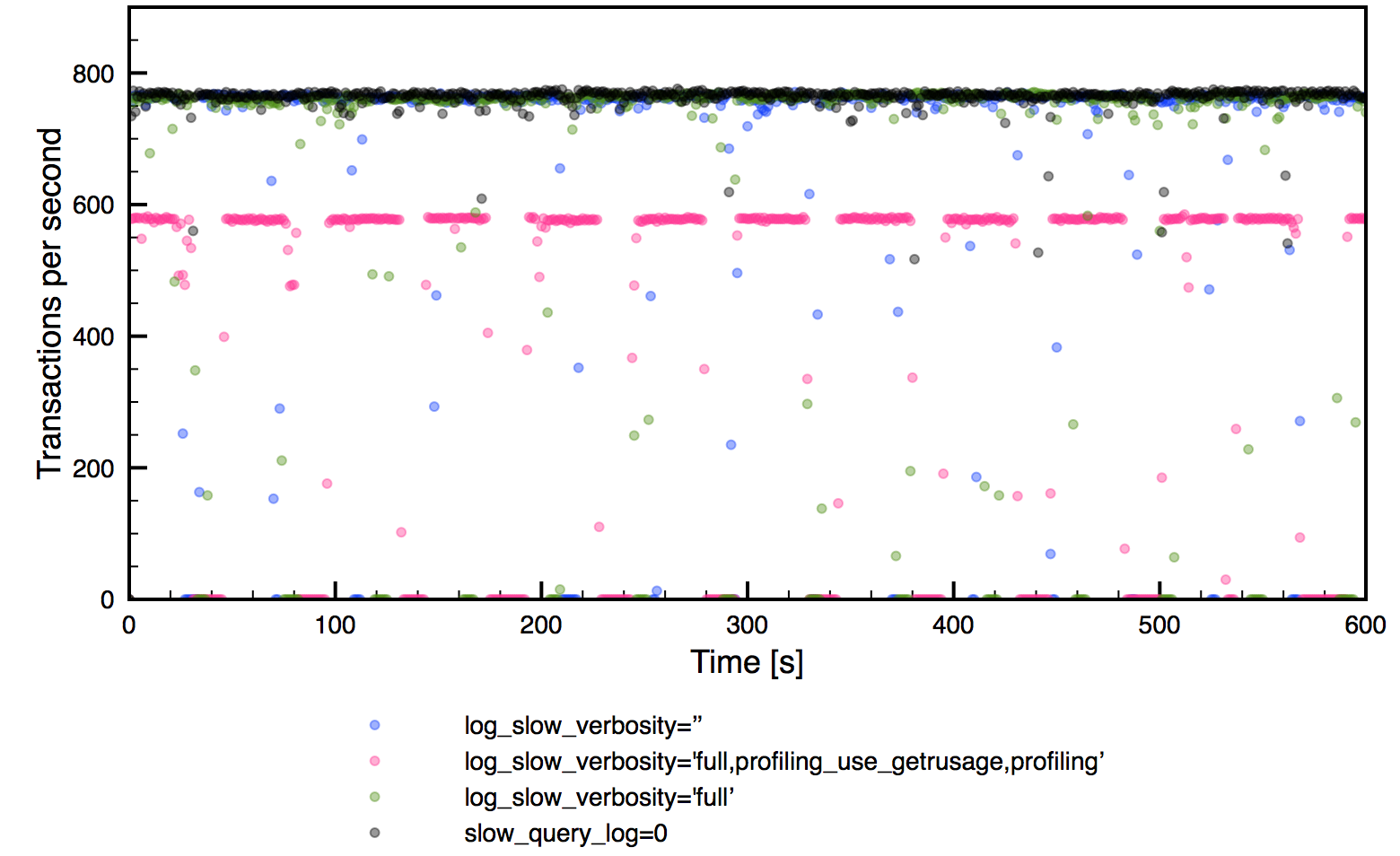
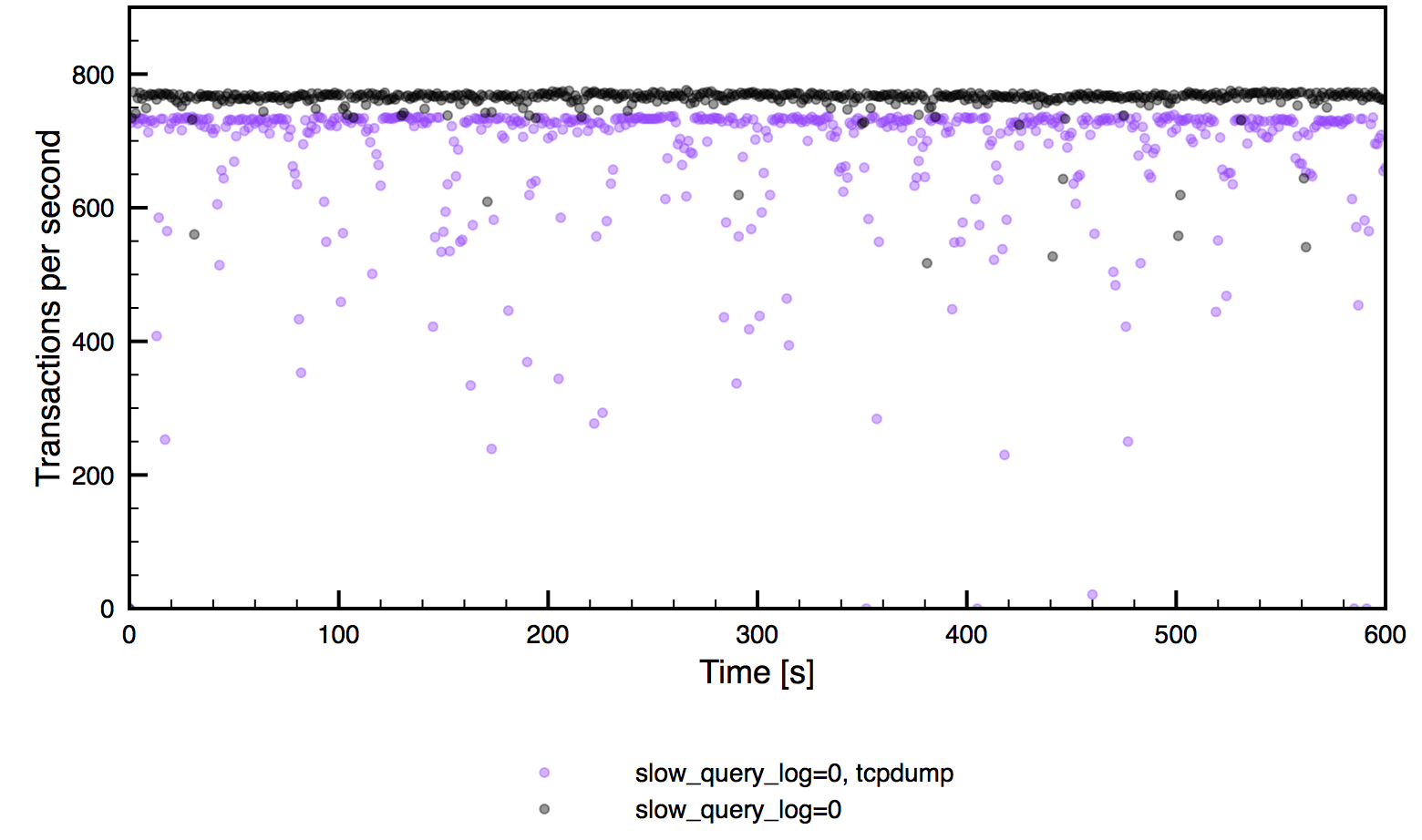
On the database side, you can also do some generic tests. For that you would need a list of queries in a slow log format. Then you can use pt-upgrade to run them on both the old and the new MySQL version, comparing the response time and result sets. In the past, we have noticed that pt-upgrade returns a lot of false positives - it may report a query as slow while in fact, the query is perfectly fine on both versions. For that, you may want to introduce some additional sanity checks - parse pt-upgrade output, grab the slow queries it reported, execute them once more on the servers and compare the results again. What you need to keep in mind that you should connect to both old and new database servers in the same way (socket connection will be faster than TCP).
Typical results from such generic tests are queries where the execution plan has changed - usually it’s enough to add some indexes or force the optimizer to pick a correct one. You can also see queries with discrepancies in the result set - it’s most likely a result of lack of explicit ORDER BY in the query - you can’t rely on rows being sorted the way they are if you didn’t sort them explicitly.
Minor version upgrades
A minor upgrade is relatively easy to perform - most of the time, all you need to do is to just install the new version using the package manager of your distribution. Once you do that, you need to ensure that MySQL has been started after the upgrade and then you should run the mysql_upgrade script. This script goes through the tables in your database and ensures all of them are compatible with the current version. It may also fix your system tables if required.
Obviously, installing the new version of a package requires the service to be stopped. Therefore you need to plan the upgrade process. It may slightly differ depending if you use Galera Cluster or MySQL replication.
MySQL replication

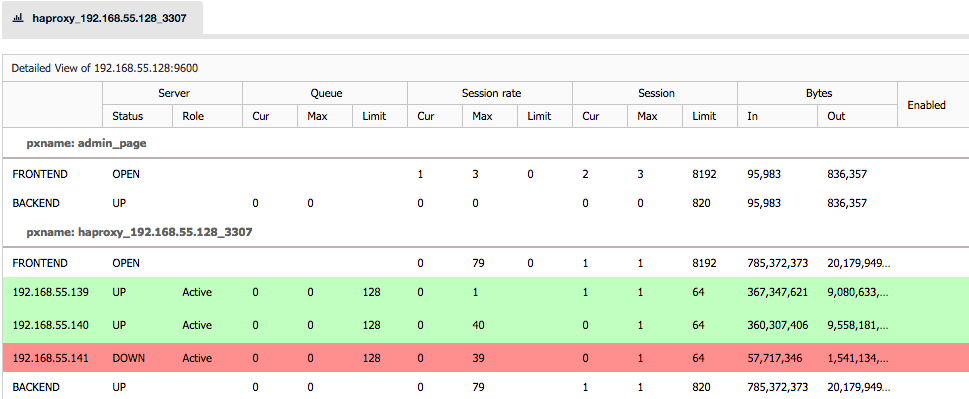
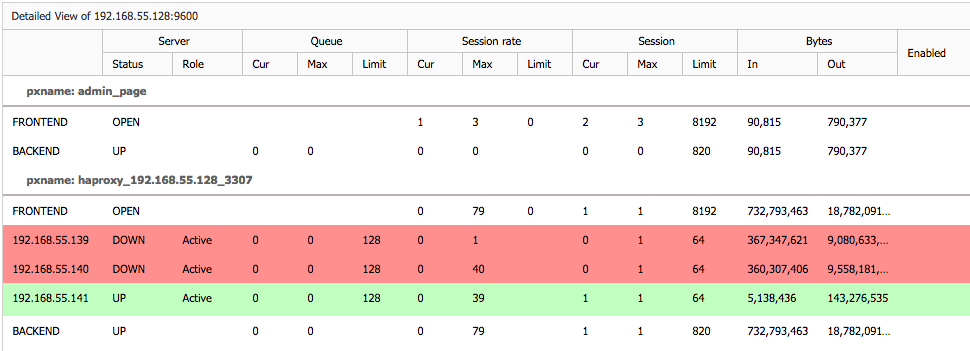
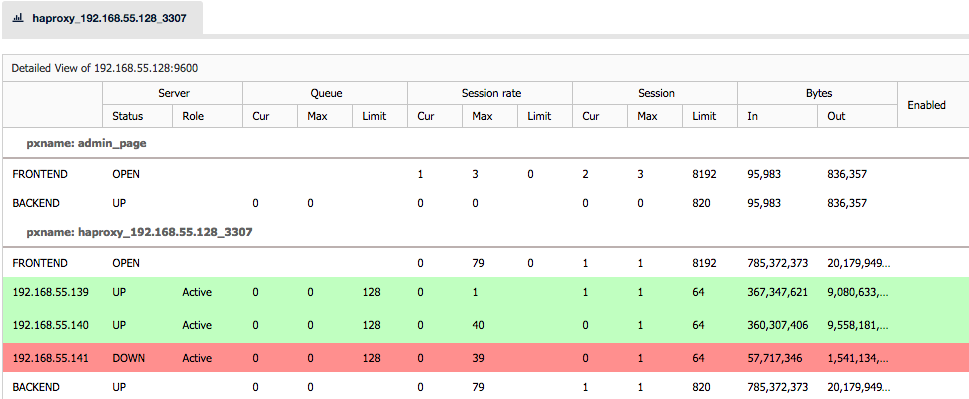
When we are dealing with MySQL replication, the upgrade process is fairly simple. You need to upgrade slave by slave, taking them out of rotation for the time required to perform the upgrade (it is a short time if everything goes right, not more than few minutes of downtime). For that you may need to do some temporary changes in your proxy configuration to ensure that the traffic won’t be routed to the slave that is under maintenance. It’s hard to give any details here because it depends on your setup. In some cases, it might not even be needed to make any changes as the proxy can adapt to topology changes on it’s own and detects which node is available and which is not. That’s how you should configure your proxy, by the way.
Once every slave has been updated, you need to execute a planned failover. We discussed the process in an earlier blog post. The process may also depend on your setup. It doesn’t have to be manual one if you have tools to automate it for you (MHA for example). Once a new master is elected and failover is completed, you should perform the upgrade on the old master which, at this point, should be slaving off the new master. This will conclude minor version upgrade for the MySQL replication setup.
Galera Cluster
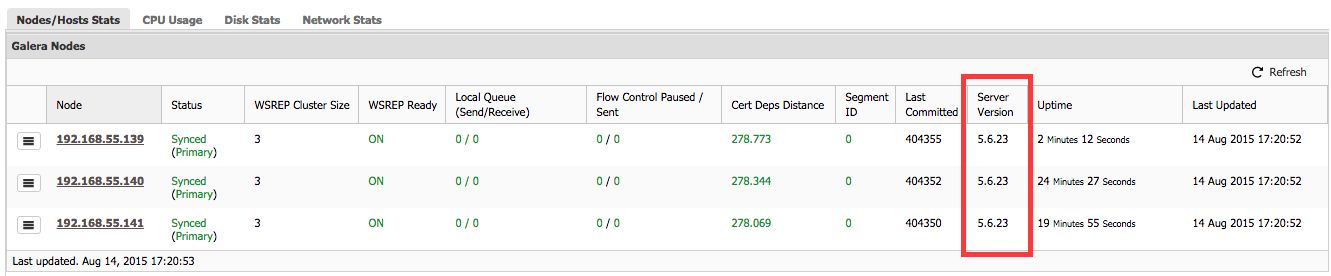
With Galera, it is somewhat easier to perform upgrades - you need to stop the nodes one by one, upgrade the stopped node and then restart before moving to the next. If your proxy needs some manual tweaks to ensure traffic won’t hit nodes which are undergoing maintenance, you will have to make those changes. If it can detect everything automatically, all you need to do is to stop MySQL, upgrade and restart. Once you gone over all nodes in the cluster, the upgrade is complete.
Major version upgrades
A major version upgrade in MySQL would be 5.x -> 5.y or even 4.x > 5.y. Such upgrade is more tricky and complex that the minor upgrades we just covered in earlier paragraphs.
The recommended way of performing the upgrade is to dump and reload the data - this requires some time (depends on the database size) but it’s usually not feasible to do it while the slave is out of rotation. Even when using mydumper/myloader, the process will take too long. In general, if the dataset is larger than a hundred of gigabytes, it will probably require additional preparations.
While it might be possible to do just a binary upgrade (install new packages), it is not recommended as there could be some incompatibilities in binary format between the old version and the new one, which, even after mysql_upgrade has been executed, may still cause some problems. We’ve seen cases where a binary upgrade resulted is some weird behavior in how the optimizer works, or caused instability. All those issues were solved by performing the dump/reload process. So, while you may be ok to run a binary upgrade, you may also run into serious problems - it’s your call and eventually it’s your decision. If you decide to perform a binary upgrade, you need to do detailed (and time-consuming) tests to ensure it does not break anything. Otherwise you are at risk. That’s why dump and reload is the officially recommended way to upgrade MySQL and that’s why we will focus on this approach to the upgrade.
MySQL replication
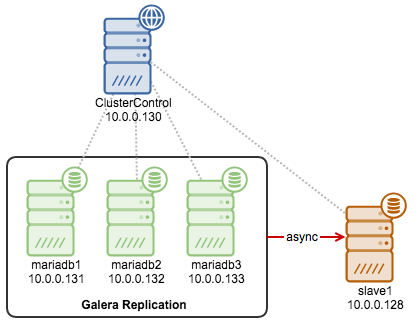
If our setup is based on MySQL replication, we will build a slave on the new MySQL version. Let’s say we are upgrading from MySQL 5.5 to MySQL 5.6. As we have to perform a long dump/reload process, we may want to build a separate MySQL host for that. A simplest way would be to use xtrabackup to grab the data from one of the slaves along with the replication coordinates. That data will allow you to slave the new node off the old master. Once the new node (still running MySQL 5.5 - xtrabackup just moves the data so we have to use the same, original, MySQL version) is up and running, it’s time to dump the data. You can use any of the logical backup tools that we discussed in our earlier post on Backup and Restore. It doesn’t matter as long as you can restore the data later.
After the dump had been completed, it’s time to stop the MySQL, wipe out the current data directory, install MySQL 5.6 on the node, initialize the data directory using mysql_install_db script and start the new MySQL version. Then it’s time to load the dumps - a process which also may take a lot of time. Once done, you should have a new and shiny MySQL 5.6 node. It’s time now to sync it back with the master - you can use coordinates collected by xtrabackup to slave the node off a member of the production cluster running MySQL 5.5. What’s important to remember here is that, as you want to eventually slave the node off the current production cluster, you need to ensure that binary logs won’t rotate out. For large datasets, the dump/reload process may take days so you want to adjust expire_logs_days accordingly on the master. You also want to confirm you have enough free disk space for all those binlogs.
Once we have a MySQL 5.6 slaving off MySQL 5.5 master, it’s time to go over the 5.5 slaves and upgrade them. The easiest way now would be to leverage xtrabackup to copy the data from the 5.6 node. So, we take a 5.5 slave out of rotation, stop the MySQL server, wipe out data directory, upgrade MySQL to 5.6, restore data from the other 5.6 slave using xtrabackup. Once that’s done, you can setup the replication again and you should be all set.
This process is much faster than doing dump/reload for each of the slaves - it’s perfectly fine to do it once per replication cluster and then use physical backups to rebuild other slaves. If you use AWS, you can rely on EBS snapshots instead of xtrabackup. Similar to the logical backup, it doesn’t really matter how you rebuild the slaves as long as it will work.
Finally, once all of the slaves were upgraded, you need to failover from the 5.5 master to one of the 5.6 slaves. At this point it may happen that you won’t be able to keep the 5.5 in the replication (even if you setup master - master replication between them). In general, replicating from a new version of MySQL to an older one is not supported - replication might break. One way or another, you’ll want to upgrade and rebuild the old master using the same process as with slaves.
Galera Cluster
Compared to MySQL Replication, Galera is, at the same time, both trickier and easier to upgrade. A cluster created with Galera should be treated as a single MySQL server. This is crucial to remember when discussing Galera upgrades - it’s not a master with some slaves or many masters connected to each other - it’s like a single server. To perform an upgrade of a single MySQL server you need to either do the offline upgrade (take it out of rotation, dump the data, upgrade MySQL to 5.6, load the data, bring it back into rotation) or create a slave, upgrade it and finally failover to it (the process we described in the previous section, while discussing MySQL replication upgrade).
Same thing applies for Galera cluster - you either take everything down for the upgrade (all nodes) or you have to build a slave - another Galera cluster connected via MySQL replication.
An online upgrade process may look as follows. For starters, you need to create the slave on MySQL 5.6 - process is exactly the same as above: create a node with MySQL 5.5 (it can be a Galera but it’s not required), use xtrabackup to copy the data and replication coordinates, dump the data using a logical backup tool, wipe out the data directory, upgrade MySQL to 5.6 Galera, bootstrap the cluster, load the data, slave the node off the 5.5 Galera cluster.
At this point you should have two Galera clusters - 5.5 and a single node of Galera 5.6, both connected via replication. Next step will be to build the 5.6 cluster to a production size. It’s hard to tell how to do it - if you are in the cloud, you can just spin up new instances. If you are using colocated servers in a datacenter, you may need to move some of the hardware from the old to the new cluster. You need to keep in mind the total capacity of the system to make sure it can cope with some nodes taken out of rotation. While hardware management may be tricky, what is nice is that you don’t have to do much regarding building the 5.6 cluster - Galera will use SST to populate new nodes automatically.
In general, the goal of this phase is to build a 5.6 cluster that’s large enough to handle the production workload. Once it’s done, you need to failover to 5.6 Galera cluster - this will conclude the upgrade. Of course, you may still need to add some more nodes to it but it’s now a regular process of provisioning Galera nodes, only now you use 5.6 instead of 5.5.